
Interpretability research already has a framework for actionability. It's called decision theory
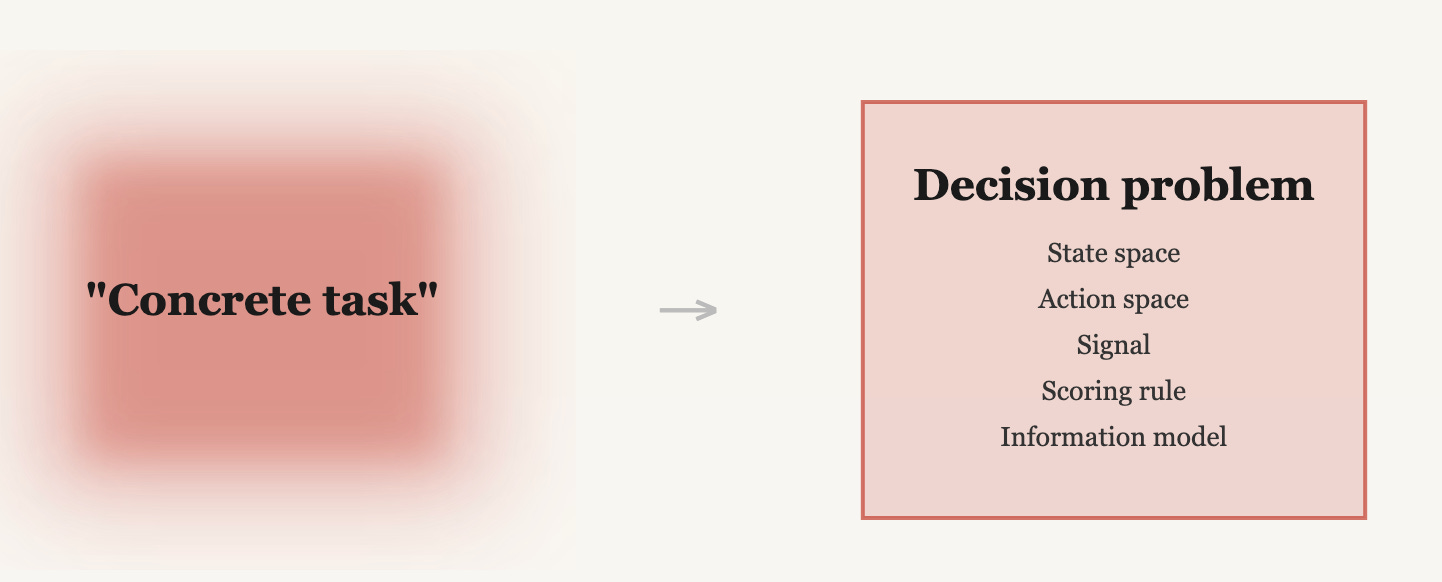
Calls for pragmatic interpretability research won't reduce ambiguity about what works unless we formalize what "concrete task" means

Seven or eight years ago I saw Chris Olah give a talk analogizing machine learning interpretability to the discovery of the microscope. If you look at interpretability research today, it’s clear that the comparison to basic science sold. Computer science may be an applied discipline, but we are not immune to envying the fundamental methods and discoveries of the hard sciences. In recent years, mechanistic interpretability has provided an outlet to channel some of this envy. In many ways, it’s been productive: by letting curiosity lead, researchers have generated new lenses into internal representations and causal dependencies in models’ computation.
Still, no researcher wants to look back one day and realize that they spent years making up problems and solutions primarily for other researchers. So it’s natural that as mechanistic interpretability and explainable AI more broadly have matured, we’d see pushback calling for more attempts to ensure that new techniques are “actionable” or “pragmatic.” Recently it’s been proposed that we should be asking whether methods like SAEs or steering vectors guide people’s actions toward practical objectives, like improving the model to make it more accurate or aligned. According to a DeepMind proposal, interpretability methods should be evaluated based on whether they are “directly solv[ing] problems on the critical path to AGI.” Another recent paper associated with an ICML 2025 workshop on “actionable interpretability,” proposes two dimensions—concreteness and validation—to characterize how actionable new insights into model behavior are. This comes with an associated checklist that asks authors to define a clear goal and audience, propose concrete interventions, and validate those interventions in realistic settings.
What neither proposal acknowledges is that decision theory already provides precise tools for this problem. We don’t have to reinvent the wheel! The same framework that formalizes rational choice can also formalize what it means to evaluate interpretability and explanation techniques.
Why is it worth learning decision theory’s formalisms to realize pragmatic interpretability? Because when we describe the goals of pragmatic or actionable interpretability work but provide only loose guidance on how to realize it, it remains ambiguous whether a given test shows that a technique worked. Researchers can choose a “concrete task”—say, whether an auditor can correctly identify a model trained on toxic data when given SAE-based feature explanations—and see whether those explanations improve accuracy relative to a baseline. But if they aren’t intentional about how they specify that task, it remains unclear how good performance could have been, or why results are unimpressive. Is it because the technique failed? The task was too easy (or hard) to begin with? The users assumed a different scoring than the one the researchers used to evaluate them?
As Ziyang Guo, Berk Ustun, and I demonstrate in this recent paper, formulating interpretability objectives in terms of decision theory has multiple benefits:
It reduces ambiguity about what task we are talking about
Without a formal specification, “detect whether a model was trained on toxic data” could mean a dozen different things depending on what information the auditor sees, how correct answers are scored, and what the base rate of toxic training is. Decision theory resolves this by formalizing a “concrete task” as a decision problem, consisting of a state space (the possible states of the world on which the decision quality depends), an action space (the set of possible actions the human can take), a signal (the information set that the decision-maker has access to as they make their decision), and a scoring rule (a function that assigns a score to any combination of action and ground truth state - essentially a loss function). When we go to evaluate some agent’s performance on that task, we can only do so relative to some ground truth dataset. So we add our final component, an information model, which is the true joint probability distribution over the signals and the state.
To take the simple example above, imagine we want to evaluate SAEs ability to help us detect whether our model has been trained on undesirable data. The uncertain state is whether the deployed model was trained with a toxicity bias, i.e., s ∈ {0,1} where s=1 indicates the training data included toxic comments (vs. a non-toxic split) The action space is a binary audit decision, a ∈ {0,1} i.e., “flag” vs “no-flag”, and the utility is accuracy, u(a,s)=1[a=s]. The signal is what the auditor gets to see per test instance: the prompt/input text, the model’s generated continuation / next-token sequence, and an SAE-based explanation consisting of the top-k SAE features (with natural-language feature interpretations), for different k. If we wanted to make the task even more “actionable,” we could redefine the state as a downstream intervention outcome—e.g., whether a mitigation informed by the SAE findings reduces toxicity on a held-out audit suite.
It reduces ambiguity about what “good” performance means, and reveals a counterintuitive fact about explanation techniques.
Once we have an unambiguous way of specifying concrete tasks, we can analyze the tasks themselves–which is critical because not all concrete tasks are equally good for evaluating new techniques.
We do this by calculating a benchmark representing the upper bound on the performance any agent, human or otherwise, could get on that task using that signal. This is the expected performance of the best possible decision-maker, a rational, Bayesian agent who knows the true data-generating process but still faces irreducible uncertainty. We can compare the difference between this benchmark and a baseline representing the best that any agent could do if they only knew the prior probability distribution over the state, which quantifies the value of information in a decision problem.
What’s surprising at first is that for typical kinds of explanations or interpretability displays people study—which are functions applied to the model and thus “garblings” of the information already carried by instance features from the perspective of a rational decision-maker—changing the specific explanation or interpretability method doesn’t change the value of information. The upper bound is a property of the task, not the specific method. While counterintuitive at first, the logic is straightforward: the best an explanation can do is help a decision-maker extract information that’s already implicit in the model’s inputs and outputs. Since explanations are functions of the model, the model’s information defines the ceiling. No visualization or feature attribution can exceed it.
What this shows us is that what we can learn from studying impacts on specific tasks depends heavily on the strength of the tests we are putting these methods through. If best case use of the information isn’t much better than what we’d expect from best case use without access to the instance level information, then we shouldn’t be evaluating on that task.
It exposes a common flaw that makes user studies virtually impossible to interpret
Whenever we want to evaluate how much an interpretability technique helps people on some concrete task, at minimum we need to communicate to them the action space, state space, scoring rule, and prior over the state. Otherwise, the decision problem is not fully defined. And from a decision theoretic perspective, we can’t learn anything from presenting people with one decision problem, but then evaluating them relative to another. However, this often happens in user studies (see e.g., our analysis of AI-assisted decision studies here): researchers will give users one scoring rule (or not describe one one at all, leaving them to guess how good performance should be defined) and then analyze the results using a different scoring rule. The problem is that the definition of good performance changes between the task and the evaluation. Optimal performance on the task the users were given will look non-optimal when the researchers analyze the results under a different scoring rule, preventing us from actually learning anything.
It explicitly connects action-based evaluation to belief-based evaluation, rather than substituting one for the other
By embracing pragmatism we don’t necessarily have to abandon questions about how new techniques impact knowledge or belief formation. Decision theory is naturally set up to allow studying beliefs corresponding to a decision problem. For the simple SAE example where the action space is whether to flag the model or not, the equivalent belief is the probability the person assigns to the model being trained on toxic data. When we run our decision study, we could elicit this as well, and compare to the Bayesian optimal beliefs. This keeps the goal grounded in taking actions in the world, while allowing us to identify why people might not be using the methods we give them as well as they could. Are they failing to get the relevant information from the explanations, or are they getting it but failing to apply it to the task? Here we can rely on the fact that for any scoring rule we use to define a decision task, there’s an equivalent proper scoring rule where the action space is instead a probabilistic belief. By using a proper scoring rule to define the belief benchmarks (and to elicit human beliefs), we ensure that we’ve provided proper incentives for true belief reporting.
***
Ultimately, if research on interpretability and explainability wants to mature toward demonstrable impacts on real world tasks, it needs criteria for what counts as a result. Formulating evaluations of new techniques in terms of decision theory eliminates the implicit theorizing that often happens in evaluation papers, where the authors define a task but can’t say how their choices impact the results they see with humans. Grounding interpretability research in statistical theory enables comparison of results—if, for example, we get conflicting results from different studies that study similar tasks (which we undoubtedly will) we can attribute this to specific components of the problem, rather than shrugging it off. We are in a much better position to accumulate empirical knowledge across studies, in addition to just populating our CVs.
Of course, this is not to say we can eliminate subjectivity: there are still many ways to set up a decision problem, and you have to choose one to study. As we show in the paper, one way to generalize slightly is to instead study behavior across categories of decision problems, such as all problems defined by a class of scoring rules. The point is not that we can avoid subjectivity, it’s that it’s going to be much harder to learn from pragmatic interpretability studies if we are not precise about the tasks we’re studying. We may still be a long way from physics, but we don’t have to be content with vague goals.
